홈페이지를 운영하다 보면 어느 순간 특정 페이지가 검색에서 사라지거나, 색인은 됐는데 순위가 떨어지는 현상을 마주하게 됩니다. 구글 서치콘솔에서 오류 알림을 받았지만 어디서부터 손대야 할지 막막한 경우도 있습니다. Screaming Frog는 사이트 전체를 로컬에서 크롤링해 기술적 SEO 오류를 한 번에 추출하는 데스크톱 진단 도구입니다. 서치콘솔이 구글 크롤러 관점의 결과를 보여준다면, Screaming Frog는 사이트 구조 자체를 직접 뜯어볼 수 있다는 점에서 역할이 다릅니다.
이번 글에서는 Screaming Frog 크롤링 결과에서 실제 SEO 오류를 찾아내고, 수정 우선순위를 정해 개선하는 실무 흐름에 대해 살펴보겠습니다.
크롤링 후 가장 먼저 확인할 SEO 오류 항목

Screaming Frog로 크롤링을 실행하면 Response Codes 탭에서 사이트 전체 URL의 HTTP 상태 코드를 한눈에 확인할 수 있습니다. 여기서 가장 먼저 필터링해야 할 항목은 Client Error(4xx)와 Server Error(5xx)입니다.
4xx 오류는 존재하지 않는 페이지로 내부링크가 연결된 상태를 의미합니다. 사용자가 깨진 링크를 클릭하면 이탈하고, 크롤러 입장에서도 크롤링 예산이 낭비됩니다. 5xx 오류는 서버 자체가 응답하지 못하는 상태로, 반복되면 구글이 해당 페이지의 크롤링 빈도를 줄이게 됩니다.
Screaming Frog와 구글 서치콘솔의 차이는 진단 범위에 있습니다. 서치콘솔은 구글봇이 실제로 방문한 페이지만 보여주지만, Screaming Frog는 내부링크 구조를 따라 사이트 전체를 순회하므로 서치콘솔에 잡히지 않는 고아 페이지나 깊은 경로의 오류까지 발견할 수 있습니다.
테크니컬 SEO 전반 점검 기준은 테크니컬 SEO 완벽 가이드, 검색엔진이 읽는 기준에서 확인하세요.
중복 메타와 타이틀 문제 진단

크롤링 결과의 Page Titles 탭과 Meta Description 탭에서 Duplicate 필터를 적용하면, 동일한 타이틀이나 디스크립션을 공유하는 페이지 목록이 즉시 추출됩니다. 중복 타이틀은 검색엔진에게 두 페이지의 차이를 구분하기 어렵게 만들고, 검색 결과에서 어떤 페이지를 노출해야 할지 혼란을 줍니다.
중복이 발생하는 대표적인 원인은 CMS에서 기본 타이틀 템플릿을 그대로 사용하는 경우, URL 파라미터로 같은 콘텐츠가 여러 주소에서 접근 가능한 경우, 그리고 페이지네이션 페이지에 동일한 메타 정보가 적용된 경우입니다.
해결 기준은 명확합니다. 모든 색인 대상 페이지는 고유한 타이틀과 디스크립션을 가져야 하고, 파라미터로 인한 중복 URL은 canonical 태그로 대표 페이지를 지정해야 합니다. Screaming Frog의 Duplicate 탭은 이 작업의 시작점으로, 수십~수백 페이지 규모의 사이트에서 수작업으로는 불가능한 전수 조사를 몇 분 안에 끝낼 수 있습니다.
리다이렉트 체인과 Canonical 충돌 잡기
리다이렉트 체인은 A 페이지가 B로, B가 다시 C로 이동하는 구조를 말합니다. Reports 메뉴의 Redirect Chains 리포트에서 전체 체인 목록과 홉 수를 확인할 수 있습니다. 구글은 301 리다이렉트가 PageRank를 온전히 전달한다고 밝히고 있지만, 체인이 길어지면 크롤링 효율이 떨어지고 색인 반영 속도가 느려집니다. 구글봇은 최대 10홉까지 따라가지만, 5홉을 넘기면 크롤링을 중단하는 경우도 보고되고 있어 가능하면 모든 리다이렉트를 최종 목적지로 직접 연결하는 것이 원칙입니다.
Canonical 충돌은 더 까다로운 문제입니다. 페이지 A의 canonical이 B를 가리키는데, B의 canonical이 다시 C를 가리키는 Canonical 체인이 대표적입니다. Screaming Frog의 Canonicals 탭에서 Canonical Chain 필터를 적용하면 이런 순환 구조를 한 번에 잡아낼 수 있습니다. 해결 방법은 모든 canonical이 최종 대표 URL을 직접 가리키도록 통일하는 것입니다.
사이트맵과 robots.txt 충돌 해결은 사이트맵과 robots.txt 설정, 크롤링을 제어하는 첫 번째 단계에서 확인하세요.
색인 차단과 크롤링 낭비 구조 점검

Screaming Frog의 Directives 탭에서는 noindex가 설정된 페이지 목록을 확인할 수 있습니다. noindex 자체는 문제가 아니지만, noindex 페이지에 내부링크가 여러 개 연결되어 있다면 크롤링 예산이 낭비되는 구조입니다. 이런 페이지는 내부링크를 제거하거나, 정말 색인이 필요 없는 페이지인지 재검토해야 합니다.
Crawl Depth 컬럼도 중요한 점검 항목입니다. 크롤 뎁스가 깊어질수록 크롤러가 해당 페이지를 발견하고 재방문하는 빈도가 낮아지는 경향이 있습니다. 일반적으로 중요 페이지는 홈페이지에서 3~5클릭 이내에 도달할 수 있도록 설계하는 것이 권장되며, 크롤 뎁스가 지나치게 깊은 페이지가 있다면 상위 페이지에서 내부링크를 추가해 접근 경로를 줄여야 합니다.
사이트맵에 등록된 URL과 실제 크롤링된 URL을 비교하는 것도 실무에서 빠뜨리기 쉬운 점검입니다. Screaming Frog에 사이트맵을 업로드한 뒤 크롤링 결과와 대조하면, 사이트맵에는 있지만 실제로는 404를 반환하는 URL이나, 크롤링에서는 발견됐지만 사이트맵에 빠진 URL을 찾아낼 수 있습니다.
속도 진단 도구 활용은 PageSpeed Insights 사용법, 점수 해석부터 개선 방법까지에서 확인하세요.
진단 결과를 개선 액션으로 전환하는 순서

크롤링 결과에서 수십 가지 오류가 동시에 나오면 어디서부터 손대야 할지 혼란스럽습니다. 수정 우선순위는 색인 영향도를 기준으로 정하는 것이 효율적입니다.
가장 먼저 처리할 항목은 색인 차단 충돌입니다. noindex와 사이트맵 등록이 모순되거나, robots.txt가 중요 페이지를 차단하고 있는 경우 해당 페이지는 아예 검색에 나타나지 않으므로 최우선으로 해결합니다. 그다음은 4xx 오류를 정리해 내부링크 구조를 정상화하고, 리다이렉트 체인을 단축해 크롤링 효율을 높입니다. 마지막으로 중복 메타 정리와 크롤 뎁스 개선 작업을 진행합니다.
Screaming Frog 크롤링과 서치콘솔 데이터를 함께 보면 뭐가 달라지나요?
서치콘솔은 구글봇이 실제로 크롤링한 결과만 보여주기 때문에, 내부링크가 없어 구글봇이 방문하지 못한 페이지는 아예 데이터에 나타나지 않습니다. Screaming Frog는 사이트 전체 구조를 독립적으로 순회하므로, 두 데이터를 대조하면 구글이 놓치고 있는 페이지와 불필요하게 크롤링하고 있는 페이지를 동시에 파악할 수 있습니다.
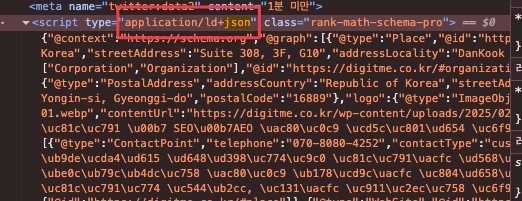
구조화 데이터 점검는 스키마 마크업(구조화 데이터) JSON-LD 실전 가이드, 검색 결과를 바꾸는 마크업 설계에서 확인하세요.
자주 묻는 질문
Screaming Frog와 구글 서치콘솔만으로 기술 진단이 충분한가요?
대부분의 중소규모 사이트에서는 이 두 도구만으로 핵심 기술 오류를 충분히 진단할 수 있습니다. Screaming Frog가 사이트 구조와 내부 오류를 잡고, 서치콘솔이 실제 색인 상태와 검색 성과를 보여주기 때문에 상호 보완적입니다. 다만 Core Web Vitals 같은 속도 지표는 PageSpeed Insights를 별도로 활용해야 합니다.
크롤링 결과에서 가장 먼저 수정해야 할 항목은?
색인 자체가 차단된 상태(noindex-사이트맵 충돌, robots.txt 오차단)를 최우선으로 해결합니다. 페이지가 검색에 나타나지 않으면 다른 최적화가 모두 무의미하기 때문입니다. 그다음이 4xx 깨진 링크, 리다이렉트 체인, 중복 메타 순입니다.
크롤링은 얼마나 자주 돌려야 하나요?
콘텐츠 업데이트가 잦은 사이트라면 격주, 변경이 적은 사이트라면 월 1회가 적절합니다. 사이트 구조를 대폭 변경하거나 새 섹션을 추가한 직후에는 즉시 크롤링을 돌려 의도치 않은 오류가 발생하지 않았는지 확인하는 것이 좋습니다.
홈페이지 기술 구조에서 어떤 문제가 검색 노출을 막고 있는지 정확히 진단받고 싶다면, 디지트미에 테크니컬 SEO 진단을 문의해 주세요.